TensorFlow入门(三) - mnist手写数字识别(可视化训练)
源代码/数据集已上传到 Github - tensorflow-tutorial-samples
这篇文章是 TensorFlow Tutorial 入门教程的第三篇文章。
在第一篇文章中,我们通过每10步打印出loss值的方式,来观察loss值的变化。但是这样做并不直观,有没有什么方式能够让整个训练的过程更加一目了然呢?tensorflow提供了tensorboard,专门来实现训练过程的可视化。
tensorboard
为了更方便 tensorflow 程序的理解、调试与优化,Google发布了一套叫做 tensorboard 的可视化工具。我们可以用 tensorboard 来展现tensorflow 图像,绘制图像生成的定量指标图以及附加数据。
tensorboard 是通过读取 tensorflow 的事件文件来运行的,因为,我们需要将可视化的数据写入事件文件,这个过程称为Summary即汇总数据,这样才能在tensorflow中看到期望的可视化效果,先展示下最终的效果。
- 网络结构图
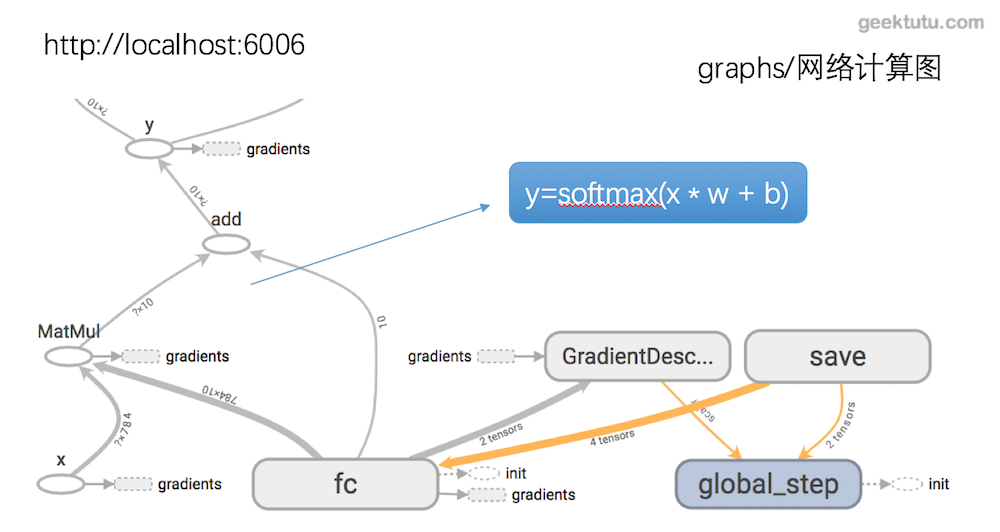
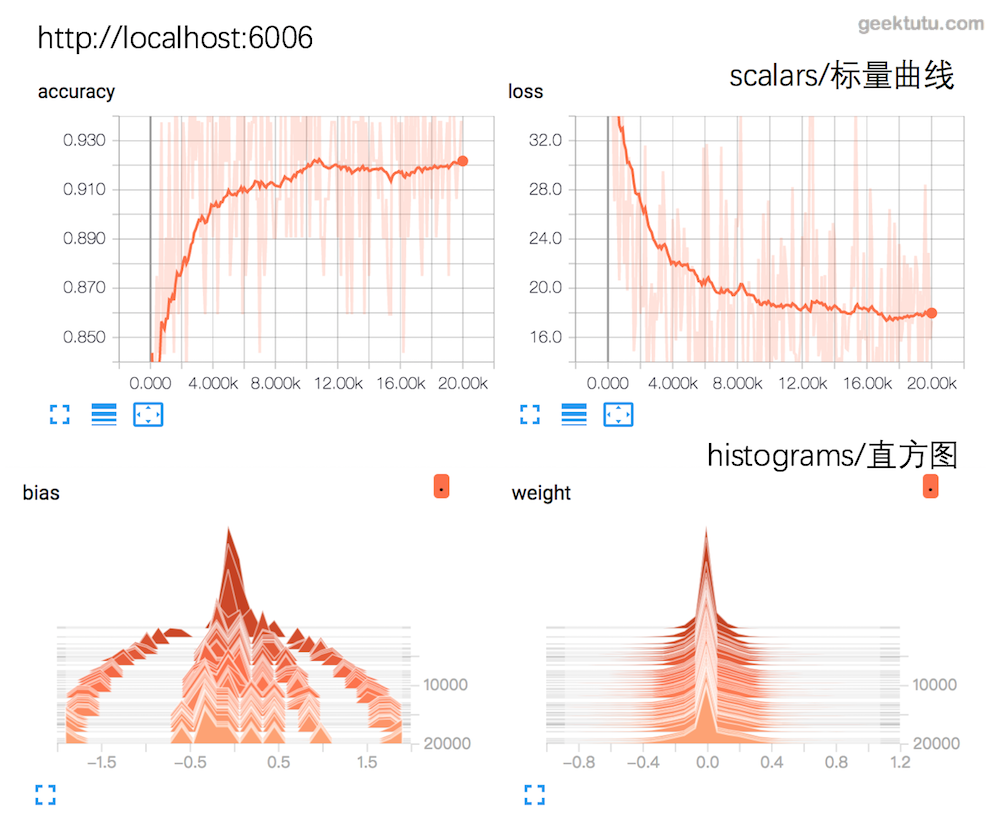
- accuray与loss,bias与weight
summary的生命周期
1. 选择需要汇总数据的张量
1 | # 例如在识别 mnist 的网络中 |
2. 汇总数据的存放位置
1 | # 存放在当前目录下的 log 文件夹中,获得文件句柄 |
3. 生成汇总数据
在tensorflow中,所有的操作只有当你执行,或者另一个操作依赖于它的输出时才会运行。我们刚才创建的这些summary node没有任何操作依赖于它们的结果,因此是不会主动生成的汇总数据的。为了生成汇总信息,可以使用tf.merge_all_summaries来合并所有的summary node。
1 | # 合并所有的summary node |
4. 保存汇总数据到文件中
可以每一步数据都保存,但是一般没有这个必要,可以选择每100步保存一次。
1 | if step % 100 == 0: |
可视化mnist网络
- 在模型(model.py)中选择需要summary的张量
1 | import tensorflow as tf |
- 训练时保存summary的数据
1 | import tensorflow as tf |
启动tensorboard
启动前,需要先训练网络,训练过程中,数据会每隔100步写入log文件夹下的文件中,这个时候,可以启动tensorboard(随tensorflow安装,不用单独安装)
1 | tensorboard --logdir=./log |
./log是summary数据存储的路径,即在tf.summary.FileWriter中传入的路径。tensorboard 开始运行后,在浏览器中输入 localhost:6006 即可看到本文最开始的效果。
觉得还不错,不要吝惜你的star,支持是持续不断更新的动力。
附 推荐
上一篇 « Pandas 数据处理(二) - 筛选数据 下一篇 » TensorFlow入门(四) - mnist手写数字识别(制作h5py训练集)



