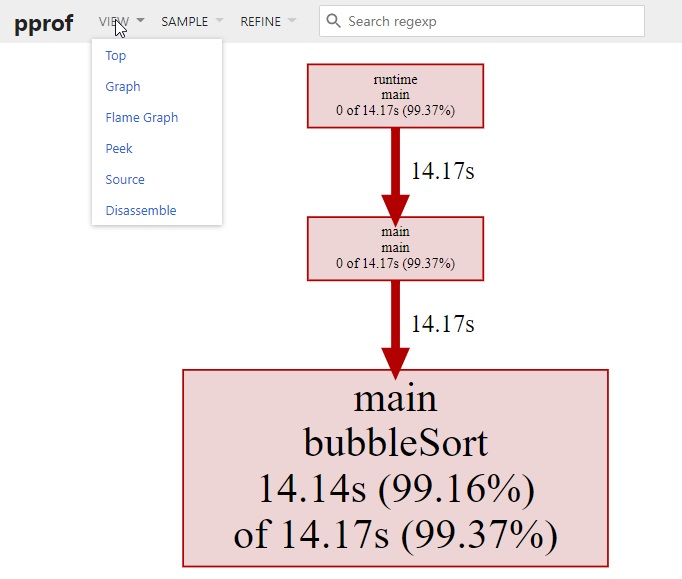
启动 CPU 分析时,运行时(runtime) 将每隔 10ms 中断一次,记录此时正在运行的协程(goroutines) 的堆栈信息。
程序运行结束后,可以分析记录的数据找到最热代码路径(hottest code paths)。
Compiler hot paths are code execution paths in the compiler in which most of the execution time is spent, and which are potentially executed very often. – What’s the meaning of “hot codepath”
$ go tool pprof cpu.pprof File: main Type: cpu Time: Nov 19, 2020 at 1:43am (CST) Duration: 16.42s, Total samples = 14.26s (86.83%) Entering interactive mode (type"help"for commands, "o"for options) (pprof) top Showing nodes accounting for 14.14s, 99.16% of 14.26s total Dropped 34 nodes (cum <= 0.07s) flat flat% sum% cum cum% 14.14s 99.16% 99.16% 14.17s 99.37% main.bubbleSort 0 0% 99.16% 14.17s 99.37% main.main 0 0% 99.16% 14.17s 99.37% runtime.main
可以看到 main.bubbleSort 是消耗 CPU 最多的函数。
还可以按照 cum (累计消耗)排序:
1 2 3 4 5 6 7
(pprof) top --cum Showing nodes accounting for 14.14s, 99.16% of 14.26s total Dropped 34 nodes (cum <= 0.07s) flat flat% sum% cum cum% 14.14s 99.16% 99.16% 14.17s 99.37% main.bubbleSort 0 0% 99.16% 14.17s 99.37% main.main 0 0% 99.16% 14.17s 99.37% runtime.main
help 可以查看所有支持的命令和选项:
1 2 3 4 5 6 7 8 9 10 11
(pprof) help Commands: callgrind Outputs a graph in callgrind format comments Output all profile comments disasm Output assembly listings annotated with samples dot Outputs a graph in DOT format eog Visualize graph through eog evince Visualize graph through evince gif Outputs a graph image in GIF format gv Visualize graph through gv ......
$ go run main.go 2020/11/22 18:38:29 profile: cpu profiling enabled, /tmp/profile068616584/cpu.pprof 2020/11/22 18:39:12 profile: cpu profiling disabled, /tmp/profile068616584/cpu.pprof
CPU profile 文件已经在 tmp 目录生成,得到 profile 文件后,就可以像之前一样,用 go tool pprof 命令,在浏览器或命令行进行分析了。
funcfib(n int)int { if n == 0 || n == 1 { return n } return fib(n-2) + fib(n-1) }
funcBenchmarkFib(b *testing.B) { for n := 0; n < b.N; n++ { fib(30) // run fib(30) b.N times } }
只需要在 go test 添加 -cpuprofile 参数即可生成 BenchmarkFib 对应的 CPU profile 文件:
1 2 3 4 5 6 7
$ go test -bench="Fib$" -cpuprofile=cpu.pprof . goos: linux goarch: amd64 pkg: example BenchmarkFib-8 196 6071636 ns/op PASS ok example 2.046s
用例执行完毕后,当前目录多出了一个 cpu.pprof 文件,接下来就可以使用 go tool pprof 命令进行分析了。
使用 -text 选项可以直接将结果以文本形式打印出来。
1 2 3 4 5 6 7 8 9 10 11
$ go tool pprof -text cpu.pprof File: example.test Type: cpu Time: Nov 22, 2020 at 7:52pm (CST) Duration: 2.01s, Total samples = 1.77s (87.96%) Showing nodes accounting for 1.77s, 100% of 1.77s total flat flat% sum% cum cum% 1.76s 99.44% 99.44% 1.76s 99.44% example.fib 0.01s 0.56% 100% 0.01s 0.56% runtime.futex 0 0% 100% 1.76s 99.44% example.BenchmarkFib 0 0% 100% 0.01s 0.56% runtime.findrunnable
pprof 支持多种输出格式(图片、文本、Web等),直接在命令行中运行 go tool pprof 即可看到所有支持的选项:
1 2 3 4 5 6 7 8 9 10
$ go tool pprof
Details: Output formats (select at most one): -dot Outputs a graph in DOT format -png Outputs a graph image in PNG format -text Outputs top entries in text form -tree Outputs a text rendering of call graph -web Visualize graph through web browser ...